


Validate your AI or Platform Idea in 40 Engineering hours. Talk to our Expert →

Why This System Exists
Athlete contracts are structurally inconsistent, heavily negotiated documents where critical financial and incentive logic is embedded in legal language, annexures, and edge cases.
Traditional contract tools fail because they assume standardized templates and static fields. This system was built to operate in non-standard, negotiated contract environments where comparability and insight do not naturally exist.
What the System Does
The Athlete Contract Intelligence Engine converts unstructured athlete agreements into a reasoning-ready knowledge layer.
At a system level, it:
The system is designed to function as an intelligence layer, not a document viewer or chatbot.
Knowledge Buddy – System Architecture
Knowledge Buddy is built as a layered intelligence architecture designed to operate on unstructured, negotiated documents rather than standardized data.
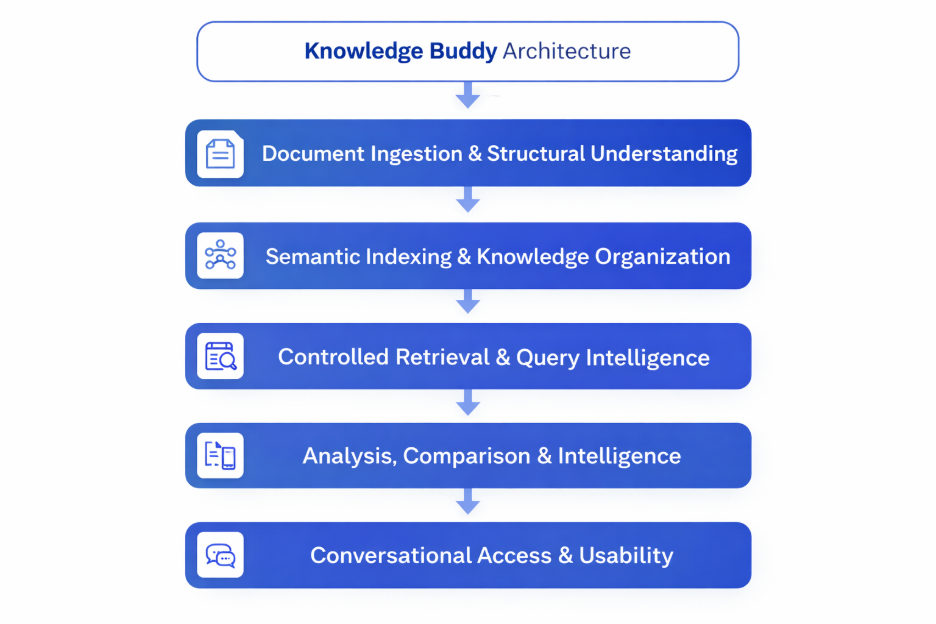
1. Ingestion & Normalization Layer
Handles scanned PDFs, digital contracts, and annexures.
2. Contract Intelligence Layer
Transforms raw text into structured, comparable knowledge.
3. Knowledge & Retrieval Layer
Enables accurate, explainable access to contract intelligence.
4. Reasoning & Query Layer
Supports natural-language interrogation and analysis.
5. Application Interface Layer
Exposes intelligence to analysts and decision-makers.
This architecture allows Knowledge Buddy to function as a persistent intelligence system, not a one-time document processor.
Hard Problems Solved
This deployment addressed challenges that are typically ignored or oversimplified in contract tools:
These constraints require domain-aware extraction and semantic reasoning rather than generic field mapping.
