Validate your AI or Platform Idea in 40 Engineering hours. Talk to our Expert →

Most organizations today don’t suffer from a lack of data. They suffer from a lack of usable knowledge.
Critical information lives inside contracts, reports, profiles, annexures, and historical records, which are locked away in PDFs and semi-structured documents. While AI adoption has accelerated, most document-focused systems still operate at a surface level: extract text, search keywords, or place a conversational layer on top.
Knowledge Buddy was engineered to address a deeper problem: Not how to read documents, but how to turn large, complex document sets into reliable, queryable knowledge systems.
At its core, Knowledge Buddy is a multi-layer document intelligence system designed to ingest, understand, organize, and reason over documents with accuracy and traceability.

Layer 1: Document Ingestion & Structural Understanding
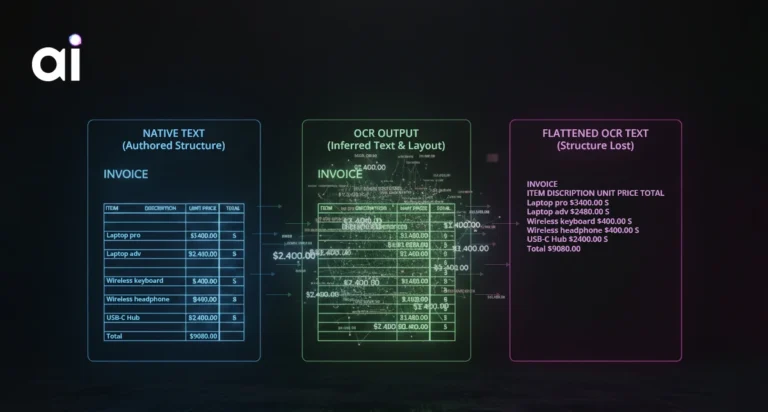
The first layer focuses on turning documents into structured knowledge, not just raw text. This includes:
Instead of flattening documents into plain text, Knowledge Buddy preserves hierarchy and intent, ensuring that meaning is not lost during ingestion.
Layer 2: Semantic Indexing & Knowledge Organization
Once documents are parsed, Knowledge Buddy organizes information based on meaning, not keywords. Key capabilities:
This allows the system to understand that two clauses written differently may still represent the same obligation and that the same term may carry different implications depending on context.
Layer 3: Controlled Retrieval & Query Intelligence
Generic document chat systems fail at scale because they retrieve too much or irrelevant context. Knowledge Buddy uses controlled retrieval pipelines that:
Natural language queries are translated into structured retrieval logic before any response is generated.
Layer 4: Analysis, Comparison & Intelligence
Beyond answering questions, Knowledge Buddy enables higher-order document intelligence. This includes:
Instead of reading documents one by one, users can reason across an entire document corpus in minutes.
Layer 5: Conversational Access & Usability
Only after the system understands documents end-to-end does the conversational layer come into play. The interface allows users to:
The conversation is not intelligence – it is an access point to intelligence.
Most document AI solutions stop at extraction or interaction. Knowledge Buddy was engineered as a knowledge infrastructure, enabling:
The same architecture that supports agreement analysis can extend to any environment where documents define decisions – from operations and compliance to performance evaluation and institutional knowledge.
Knowledge Buddy demonstrates what becomes possible when documents are treated not as files, but as living knowledge assets.
By combining structured ingestion, semantic understanding, controlled retrieval, and intelligent analysis, it enables organizations to move from document review to document-driven decision-making.