Validate your AI or Platform Idea in 40 Engineering hours. Talk to our Expert →
Most document intelligence conversations treat ingestion as a mechanical step- upload a file, pass it to OCR, and move on. In practice, ingestion is the most decisive phase of the entire system. It determines not only what the models will see, but also what they will never be able to recover.
The journey from documents to knowledge does not begin with extraction or reasoning. It begins with understanding what kind of document has entered the system and choosing the right transformation path before any intelligence is applied.
Before preprocessing, before OCR, before classification or extraction, an intelligent system must answer a deceptively simple question:
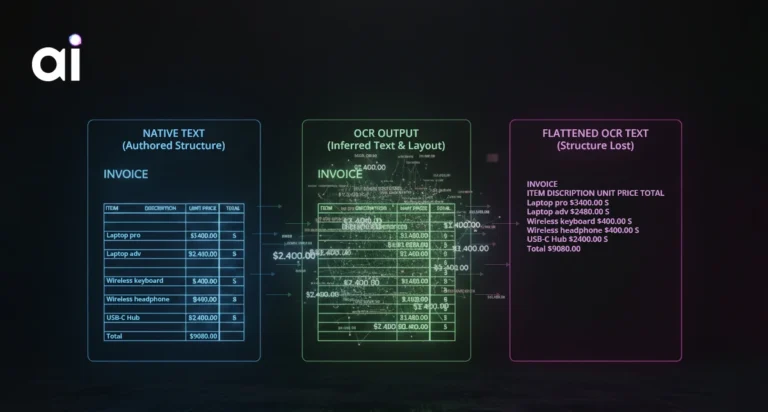
This is not about file extensions. A PDF may contain clean, machine-readable text or it may be nothing more than a scanned image wrapped in a container. An image may be a photograph of a form, a faxed contract, or a digitally generated diagram. Treating ingestion as a uniform pipeline assumes all documents behave the same and that assumption silently breaks systems.
Ingestion is therefore a classification problem, not a transport problem. The system must identify the document’s origin and properties before deciding how to process it.
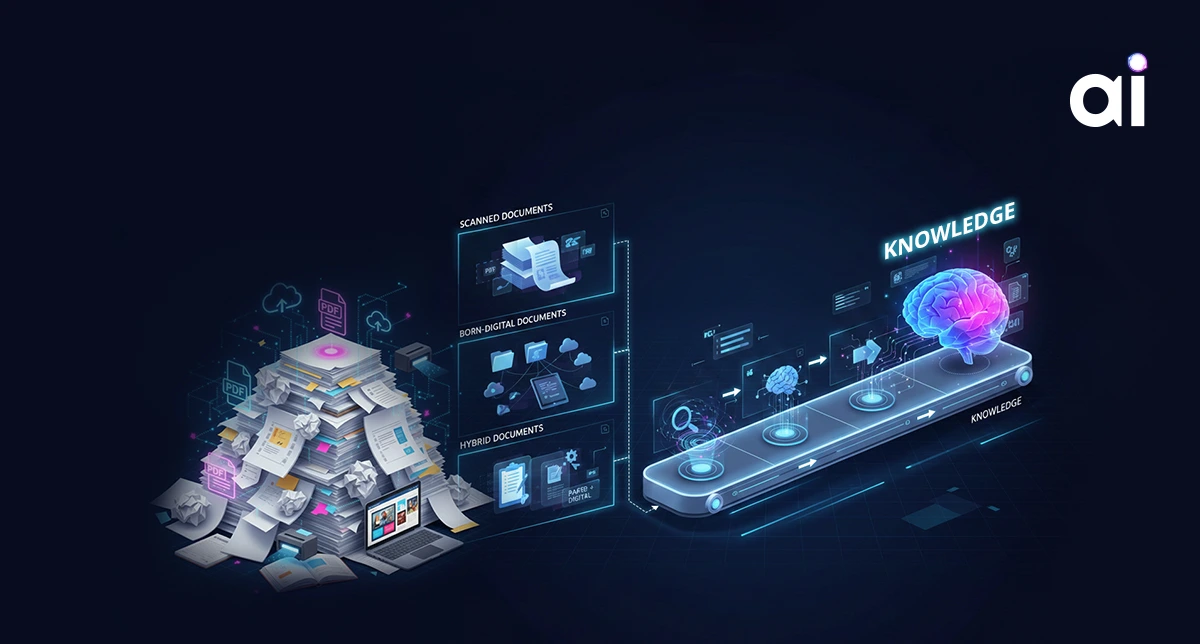
At a fundamental level, documents enter systems in three forms, each with very different implications.
Born-digital documents are created in software. They contain a native text layer, layout information, fonts, and often metadata. Their structure already exists and must be preserved.
Scanned documents are images of documents. They contain pixels, not text. Any structure or semantics must be inferred visually, and errors introduced at this stage are difficult to reverse.
Hybrid documents combine both. A single PDF may contain digitally generated text pages, scanned signatures, embedded images, or appended fax pages. These documents are common in enterprises and are also where many pipelines quietly fail.
The critical insight is that origin does not equal format. A PDF tells you nothing about whether the document is readable or meaningful to a machine.
Preprocessing is often described as a generic cleanup step. It is conditional transformation. The goal of preprocessing is different depending on what entered the system.
Applying the same preprocessing steps to both leads to predictable damage. Rasterizing digital PDFs destroys structure. Running OCR on clean text introduces errors. Skipping enhancement on scans leaves models struggling with noise that could have been corrected early.
Preprocessing must therefore branch based on document origin, not sit as a single linear stage.
Born-digital documents already contain high-quality information. The system’s job is not to “improve” them visually, but to extract and preserve what already exists.
Typical preprocessing here focuses on validating and normalizing:
A common anti-pattern is converting born-digital documents into images and re-running OCR. This discards precise text, breaks layout fidelity, and replaces certainty with probabilistic guesses. Once structure is lost, no downstream model can restore it perfectly.
Scanned documents require a fundamentally different approach. Here, preprocessing is not optional, it is the primary signal recovery phase.
Key steps often include:
Every transformation introduces trade-offs. Over-aggressive cleaning may erase faint characters or stamps. Under-processing leaves OCR struggling with artifacts that humans subconsciously ignore. The goal is not visual perfection, but machine-legible consistency.
Hybrid documents expose the weakness of rigid pipelines. When a system assumes a single preprocessing path per document, hybrid inputs force a bad compromise.
Effective handling requires:
Many enterprise failures trace back to hybrid documents being treated as purely scanned or purely digital. The result is partial corruption that looks random downstream but is entirely systematic upstream.
Mistakes at ingestion rarely fail loudly. They fail quietly and propagate.
A wrong origin classification leads to the wrong preprocessing path. This degrades OCR or corrupts text. Classification models then operate on distorted inputs. Extraction confidence drops, but often without clear explanations. Humans are pulled in to review results that should have been reliable.
At this point, teams often retrain models, adjust prompts, or add heuristics, none of which fix the original error. What appears to be a model problem is an early pipeline misroute.
No system can reason over information that never survived ingestion. No model can infer structure that was destroyed during preprocessing. Intelligence does not begin with AI models it begins with faithful transformation of input into machine-usable form.
Ingestion is not the start of the pipeline in a chronological sense. It is the point at which the ceiling of understanding is set.