Validate your AI or Platform Idea in 40 Engineering hours. Talk to our Expert →

Most teams first encounter document intelligence through individual capabilities. OCR reads text. RPA moves data. Analytics interpret patterns.
Each works well in isolation. Problems start when they are expected to behave like a system. Reliability drops, not because models are weak, but because coordination is missing. This gap is why Intelligent Document Processing (IDP) exists.
OCR focuses on perception, RPA focuses on execution and ADP focuses on analysis.
IDP sits above them. Its role is to decide what runs, in what order, and under what constraints. Instead of adding intelligence, it provides structure. That structure is what turns disconnected capabilities into a system that behaves predictably in production.
IDP is often introduced as a simple pipeline: documents go in, meaning comes out, actions follow. This explanation is convenient, but incomplete.
In real environments, documents rarely move in a straight line. Humans intervene. Confidence fluctuates. Corrections need to flow backward as well as forward. What appears linear on a slide behaves like stacked responsibilities in practice.
This is where pipeline thinking begins to break and layered thinking becomes necessary.
Most IDP systems touch a familiar set of concerns:
The insight is not the list itself. It is that each concern introduces different assumptions and failure modes. Treating them as interchangeable steps hides important design decisions.
Layer 1: From Documents to Identity
Before intelligence is applied, documents exist as physical artifacts. Scans, PDFs, images, and emails arrive with noise, versions, and missing context.
Decisions made during ingestion quietly shape everything downstream. Preprocessing affects OCR quality. Metadata handling affects traceability. Classification belongs here, because it defines what kind of document the system believes it is handling and which logic is even allowed to run.
Errors at this layer rarely look dramatic, but they propagate widely.
Layer 2: From Text to Structure
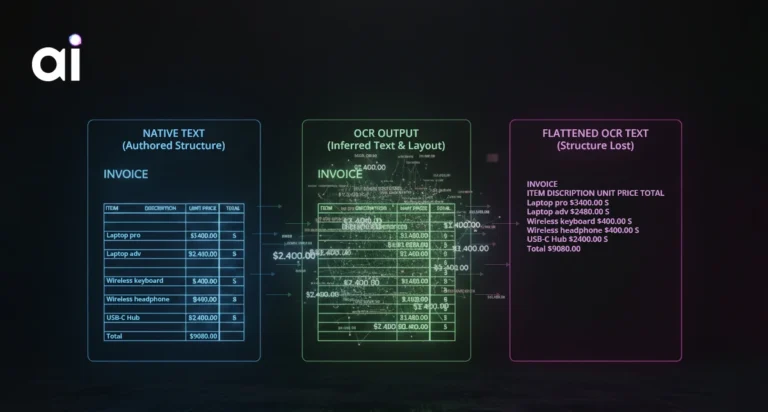
OCR converts visual signals into text, but it does so probabilistically. Layout understanding adds structure by identifying sections, tables, and relationships.
This structure is not cosmetic. It constrains meaning. Without it, semantic interpretation becomes fragile. Numbers lose anchors. Clauses lose scope. Confidence increases while correctness drops.
Layer 3: Meaning and Knowledge
Extraction and semantic understanding are often conflated, but they solve different problems. Extraction focuses on surfacing reliable facts. Semantic understanding focuses on interpreting those facts within context.
How this information is stored then determines how it can be used. Structured representations preserve constraints. Semantic representations preserve similarity. Neither is universally better. The choice defines what the system can reason about later.
Humans and Feedback as a System Layer
Human involvement is not an exception case. It is part of the system’s design. Two questions matter here:
Confidence must be explicit. Corrections must return to the layer responsible for the error. Without this separation, systems either stagnate or degrade quietly.
Thinking about document intelligence in layers changes how systems are designed, evaluated, and improved. It shifts the focus away from individual model performance and toward how responsibilities are separated and coordinated over time.
When ingestion, structure, meaning, storage, and feedback are treated as distinct concerns, failures become easier to diagnose and systems become easier to evolve. When they are collapsed, intelligence appears to work—until scale, variability, or human intervention exposes the cracks.
IDP systems that last are rarely the ones with the most advanced models. They are the ones whose architecture reflects the realities of documents, workflows, and uncertainty. Layered thinking is not an abstraction. It is a practical response to how document intelligence actually behaves in production.