Validate your AI or Platform Idea in 40 Engineering hours. Talk to our Expert →
Enterprise AI discussions often begin with a convenient simplification: enterprise knowledge is treated as “unstructured text” that can be embedded, indexed, and queried with a conversational interface.
This assumption makes prototypes easy to build and demos easy to sell. It also hides the real complexity of enterprise knowledge and explains why many document AI systems fail once they move beyond experimentation.
Enterprise documents are not created to merely describe information. They exist to encode intent, constraints, risk, and accountability in a form that can withstand legal scrutiny, operational execution, and regulatory review. Language is only the visible layer of this system.
Documents are typed knowledge artifacts, not interchangeable files
In an enterprise environment, documents differ fundamentally by purpose. A contract defines enforceable commitments, a policy defines eligibility and exclusions, and an SOP defines executable steps. Although they may share similar language and formatting, they follow different internal logic.
Each document type carries:
When systems treat all documents as generic text, they erase these distinctions. The result is a loss of semantic fidelity that no amount of downstream prompting can recover.
Meaning is inseparable from document context
Enterprise language is intentionally reused across domains, but meaning is not transferable without context.
A term like “termination” may:
Without understanding the document type and domain, systems cannot determine which interpretation applies. Embeddings can group similar phrases, but they cannot enforce the correct semantic frame.
Structure exists, but not where most systems look
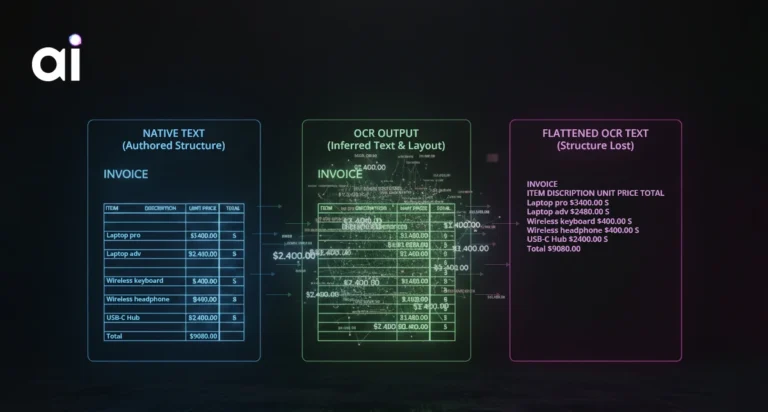
Most document-processing pipelines assume structure is visible- headings, paragraphs, lists, or tables. These elements help humans navigate documents, but they do not define how meaning is constructed.
In enterprise documents, structure is often implicit:
This structure is expressed through language and convention, not layout. Systems that rely only on visual or positional cues capture text, but miss logic.
Why generic RAG pipelines fail quietly
Most AI-on-documents systems rely on a familiar pattern: chunk the text, retrieve similar passages, and generate answers. This approach optimizes for fluency and recall, not correctness.
These systems typically:
The failure mode is not obvious errors, but plausible answers that are structurally wrong. This is the most dangerous kind of failure in enterprise contexts.
What document intelligence requires
True document intelligence begins before retrieval or generation.
It requires:
This is why systems like Knowledge Buddy treat enterprise documents as knowledge systems, not as raw inputs for conversational interfaces.
Closing perspective
Enterprise knowledge is not unstructured text waiting to be queried. It is structured intent expressed through language, shaped by legal, operational, and regulatory forces.
If a system cannot explain what type of document it is reading, what role a section plays, and why an answer is valid within that context, it is not a document intelligence- it is text prediction with confidence.